Challenge
Lors d’un hackathon consacré aux usages de l’intelligence artificielle pour l’analyse de données, l’objectif était d’explorer un problème fréquent dans le monde de la donnée et du journalisme :
Une grande partie des informations publiées dans les rapports, les médias ou les présentations existe uniquement sous forme de graphiques ou d’infographies.
Ces visualisations contiennent des données précieuses, mais elles sont souvent impossibles à réutiliser directement, car les chiffres ne sont pas accessibles sous forme structurée.
La question explorée pendant le hackathon était donc :
Peut-on utiliser des modèles d’IA multimodaux pour reconstruire un dataset à partir d’une visualisation ?
Le défi consistait à construire en peu de temps un MVP capable d’analyser différents types de graphiques et d’en extraire les valeurs.
Solution proposée
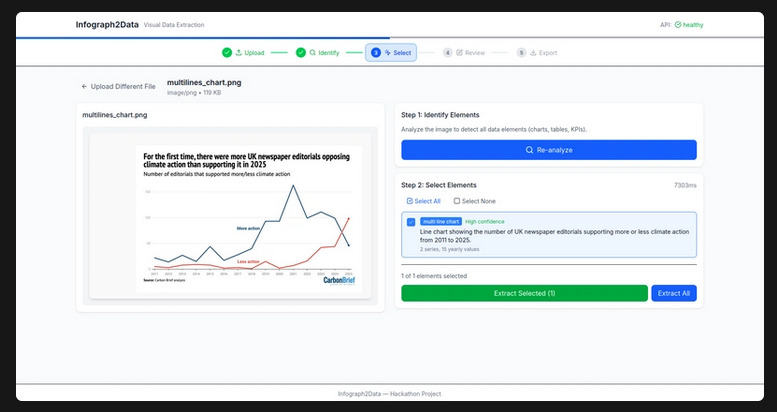
Le prototype Infograph2Data permet de transformer certaines visualisations en datasets exploitables.
Le workflow est volontairement simple :
- L’utilisateur importe une image ou un PDF contenant une visualisation
- L’application identifie les éléments graphiques présents
- Un modèle multimodal analyse la visualisation
- Les données détectées sont converties en tableau structuré
- L’utilisateur peut exporter le résultat
Le MVP supporte actuellement plusieurs formats d’entrée :
- captures d’écran de graphiques (PNG, JPG)
- infographies
- PDF contenant des visualisations
L’extraction fonctionne notamment avec :
- line charts
- bar charts
- stacked bar charts
- grouped bar charts
- pie charts
- panneaux KPI simples
Le système peut également indiquer si une valeur provient d’une annotation visible ou d’une estimation basée sur les axes, afin de distinguer les données certaines des valeurs approximées.
Technologies & Outils
Backend
- Python
- FastAPI
- Pydantic
- Pipeline d’extraction modulaire
Intelligence artificielle
- Modèles multimodaux OpenAI
- Analyse d’images et de graphiques
- Extraction structurée en JSON
Traitement de documents
- Poppler / pdf2image pour convertir les PDF en images analysables
Qualité du code
- pytest
- Tests unitaires et d’intégration
- Couverture de tests > 90 %
Déploiement
- Docker
- Hugging Face Spaces pour les démonstrations live
Résultat / Prix (si applicable)
Le projet a permis de construire un MVP fonctionnel démontrant qu’il est possible d’utiliser les modèles multimodaux pour reconstruire des datasets à partir de visualisations.
Même si l’extraction reste approximative dans certains cas (notamment lorsque les valeurs doivent être estimées à partir des axes), le prototype montre que ces approches peuvent :
- accélérer la récupération de données publiées uniquement sous forme graphique
- faciliter la réutilisation de données issues d’infographies
- ouvrir de nouvelles pistes pour le journalisme de données et la recherche.
Liens utiles (Repo, Demo, etc.)
- Repository GitHub :
- Demo (Hugging Face Space) :
- Article technique :